Introduction
Cloud environments provide elastic and on-demand resources for customising data storage, processing, and communication, playing an increasingly important role in developing applications [1]. Emerging cloud applications like decentralised applications (DApps) are increasing. However, because of the inherent dynamism of clouds, performance anomalies of cloud applications, such as degraded response time, severely affect the quality of user experience. Performance anomalies occur through many factors, such as resource contention, workload bursts, network attacks, etc. When the root cause of a performance anomaly is determined, cloud providers can follow suitable adaptation strategies, such as adding a VM. Therefore, adaptive systems are critical for the rapid recovery and loss mitigation of cloud applications. At the same time, such systems should detect performance anomalies, localise root causes, and execute adaptation strategies.
Requirements and Challenges
Researchers have been studying adaptive systems for several years. Ibidunmoye et al. reviewed performance anomaly detection and bottleneck identification methods in adaptive systems. They formulated fundamental research problems, categorised methods, and proposed research trends and open challenges [2]. Based on previous research, an adaptive system for cloud applications must perform continuous runtime status monitoring, abnormal performance phenomena detection (e.g., degradation), performance anomaly cause identification, adaptation strategies, and implementation. Therefore, we can summarise four components of an adaptive system as detailed below.
Monitoring data
Monitoring data includes application-level and system-level data for cloud applications. For example, we can use application-level data such as response time to detect performance anomalies. However, it’s hard to capture the underlying cloud environments’ status and exploit the root causes of performance anomalies with single-variable application-level data. System-level data includes underlying resources, such as CPU, memory, disk, and network, which can affect the performance of cloud applications heavily. For an adaptive system, integrating monitoring data is important for subsequent analysis.
Performance anomaly detection
Performance anomaly detection is the process of detecting abnormal performance phenomena and predicting anomalies to forestall future incidents. Existing anomaly detection methods use statistical and machine learning-based methods to improve detection accuracy, but their performance is inconsistent in cloud environments. For example, scaling cloud infrastructures will change the distribution of monitoring data, severely affecting detection performance. Robustness is equally important as accuracy, considering the diversity of monitoring data for performance anomaly detection in cloud applications.
Root cause localisation
Root cause localisation is to identify the root causes of performance anomalies. Due to the complex dependencies of cloud applications, it is difficult for operators to identify root causes. Traditionally, operators perform diagnoses for cloud applications manually, which is complicated and time-consuming. Researchers proposed machine learning, pattern recognition, and graph-based methods using data from cloud applications, such as logs, requests execution tracing data, and metrics to localise root causes. However, existing approaches are still under development, and most of them are coarse-grained, focusing on service-level or container-level faults. Identifying root causes with fine-grained (metric-level) is necessary to provide better adaptation strategies.
Adaptation strategies
Based on the identified root causes of performance anomalies, adaptation strategies can optimally determine the type and quantity of required resources. Various techniques range from discrete optimisation algorithms to control-theoretic approaches, such as threshold and rule-based. However, traditional adaptation methods are not suited to the multiple components of cloud applications. Model-based methods, such as reinforcement learning, are promising candidate solutions that should be the subject of future research.
The adaptive system
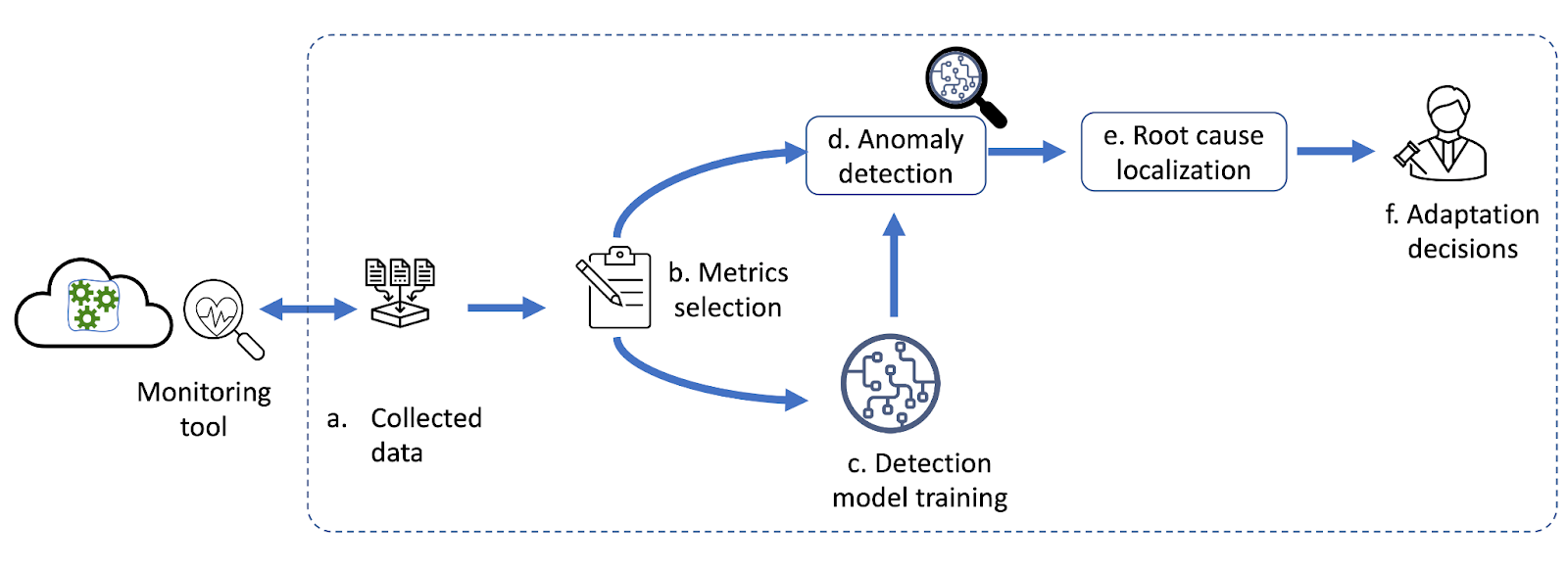
To meet the requirements and challenges of an adaptive system, we designed a general system for cloud applications. The adaptive system works in several steps. First, (a) it continuously collects multivariate time-series monitoring data, including application-level and system-level data. In addition, model training may use labels to indicate application performance anomalies. For collected data, (b) the process of metrics selection will filter multivariate data via feature selection or extraction methods. Monitoring data usually contains noise, introducing unnecessary variance into the model. Therefore, feature selection methods such as correlation analysis or feature extraction methods such as principal component analysis to identify relevant data and dimensionality reduction are needed.
Subsequently, (c) selected metrics are used for the offline training of the performance anomaly detection method. We can use unsupervised learning methods like Isolation Forest and K-nearest neighbour on non-labelled data. When several labels are available, our approach integrates a deep ensemble method that integrates existing detection methods – and has outperformed them in detection accuracy and robustness.
Next, we feed real-time monitoring data into the trained model for (d) online performance anomaly detection. Once an anomaly occurs, (e) we perform the root cause localisation to discover the causes of the anomaly. We developed the root cause localisation method with graph-based methods. Graph-based methods can identify root causes with fine-grained granularity and visualise the issue with a visual graph. We use the Peter and Clark algorithm to build a causality graph between monitoring metrics and random walk to localise root causes. Finally, (f) localisation results are helpful for the rapid recovery of cloud applications. For example, if the root cause is high CPU usage, adaptation strategies may consider scaling VMs, like adding one VM.
Conclusion
In summary, the adaptive system’s primary goal is healthy cloud applications execution, which entails the following objectives:
- Continuous monitoring of a cloud application’s runtime status, collecting multiple monitoring data;
- Data preprocessing for monitoring data, such as data dimension reduction;
- Improved accuracy and robustness for performance anomaly detection based on monitoring data;
- Integration of existing detection methods with ensemble learning;
- Localising root causes of performance anomalies accurately with fine-grained granularity using graph-based methods;
- Determine adaptation strategies based on localisation results and requirements, such as cost.
The CONF tool develops an adaptive system for cloud applications and details each integrated component. In the future, we will continue to improve our system and create an automated adaptive system, which is our goal in the EU ARTICONF project.
Reference
[1] Zhou, Huan, et al. “A blockchain based witness model for trustworthy cloud service level agreement enforcement.” IEEE INFOCOM 2019-IEEE Conference on Computer Communications. IEEE, 2019.
[2] Ibidunmoye, Olumuyiwa, Francisco Hernández-Rodriguez, and Erik Elmroth. “Performance anomaly detection and bottleneck identification.” ACM Computing Surveys (CSUR) 48.1 (2015): 1-35.
This blog post was written by The University of Amsterdam team in May 2022.
< Thanks for reading. We are curious to hear from you. Get in touch with us and let us know what you think. >